Коротко
RAG часто объясняют слишком просто: разбили документы на куски, сделали embeddings, положили их в vector database, нашли похожий фрагмент и отдали его модели. Для демо этого хватает. Для рабочей системы, где есть артикулы, VIN, заказы, таблицы, регламенты, звонки и права доступа, одной векторной похожести быстро мало.
Векторный поиск хорошо ловит смысл. Пользователь спросил “как оформить возврат”, система нашла политику возвратов, даже если слова не совпали. Но точные номера заказов, коды запчастей, даты, комплектации, имена, штаты, версии документов и редкие термины часто лучше находит полнотекстовый поиск.
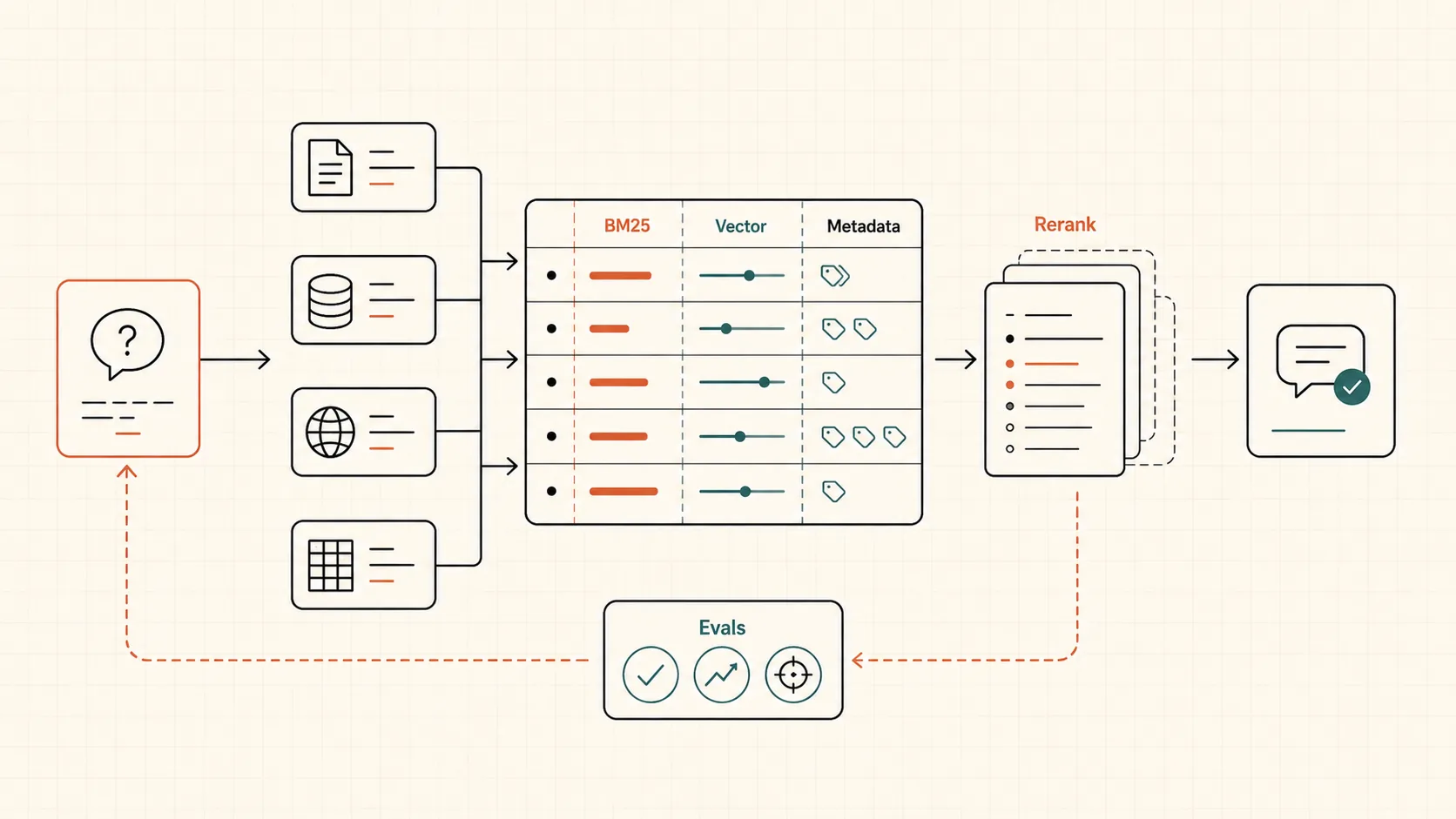
Production RAG поэтому почти всегда становится поисковой системой, а не “чатом с документами”. Там есть ingestion, нормализация данных, metadata, BM25, vector search, fusion, reranking, сбор контекста, ссылки на источники, правила отказа и evals.
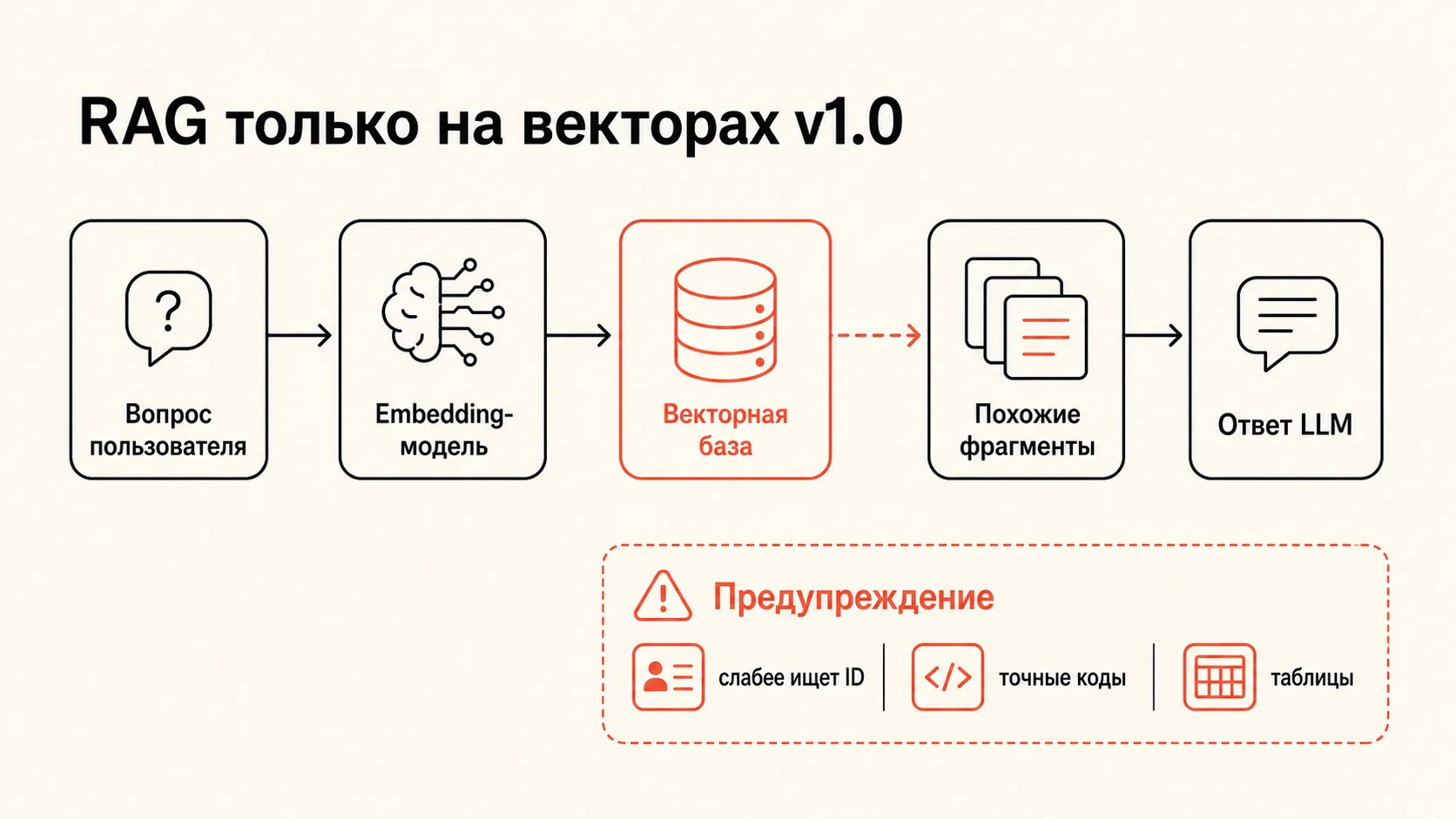
В проекте AI CRM это проявилось очень быстро. Первая версия на векторном поиске была технически “правильной”, но для менеджеров стала шумной: во время разговора с клиентом подтягивались нерелевантные подсказки. Система мешала, потому что похожий текст не всегда был правильным источником.
Дальше качество выросло не от одной магической модели, а от инженерной работы вокруг retrieval: feedback loop от пользователей, синтетические проверки, полнотекстовый поиск по точным ID, перевод запросов, HyDE, metadata-фильтры, SQL по структурированным данным и agentic RAG для составных вопросов.
Что RAG делает на самом деле
RAG расшифровывается как Retrieval-Augmented Generation. Простыми словами: модель отвечает не только “из памяти”, а получает найденные фрагменты из ваших источников и строит ответ на их основе.
Но важен не сам факт, что мы “подкинули документы”. Важен путь:
- Источники нужно забрать из файлов, CRM, базы, таблиц, почты, звонков или внутренней системы.
- Данные нужно привести в форму, по которой можно искать: текст, chunks, metadata, версии, права доступа.
- Запрос пользователя нужно понять и иногда переписать.
- Поиск должен достать не просто похожие, а полезные кандидаты.
- Результаты нужно объединить, переупорядочить и отфильтровать.
- Модель должна ответить с опорой на контекст и отказаться, если источников не хватает.
- Качество нужно мерить отдельно для retrieval и отдельно для финального ответа.
Вот почему фраза “нам нужна векторная база” почти всегда слишком рано сужает задачу. Векторная база — только один компонент, а остальные компоненты заметно влияют на стоимость внедрения ИИ.
Почему embeddings не решают всё
Embeddings превращают текст в числовой вектор. Если два текста близки по смыслу, их векторы обычно оказываются рядом. Это мощно, когда пользователь формулирует вопрос живым языком.
Например:
- “как вернуть товар” может найти “политику возвратов”;
- “что делать, если сотрудник заболел” может найти HR-инструкцию по больничному;
- “какая гарантия на услугу” может найти раздел договора с гарантийными обязательствами.
Но векторная близость слаба там, где ответ зависит не от общего смысла, а от точного совпадения:
S12345как номер заказа;DSK-567как артикул детали;2023 GMC Terrain SLT AWDкак конкретная комплектация;Californiaкак штат доставки;- дата, версия, VIN, номер договора или внутренний код.
Если пользователь спрашивает “подойдёт ли эта деталь к SUV 2021 года?”, система должна найти не “похожую статью про детали”, а совместимость по конкретной модели, году, серии, заказу и правилу. Иногда обычный полнотекстовый поиск или SQL-фильтр честнее, чем самый красивый embedding.
Как выглядит production RAG
В рабочем RAG обычно есть несколько параллельных способов найти кандидатов. BM25 ловит точные слова и коды. Vector search ловит смысл. Metadata-фильтры сужают выдачу по дате, типу документа, клиенту, товару, роли пользователя или статусу заказа. Потом результаты объединяются, часто через Reciprocal Rank Fusion, и проходят reranking.
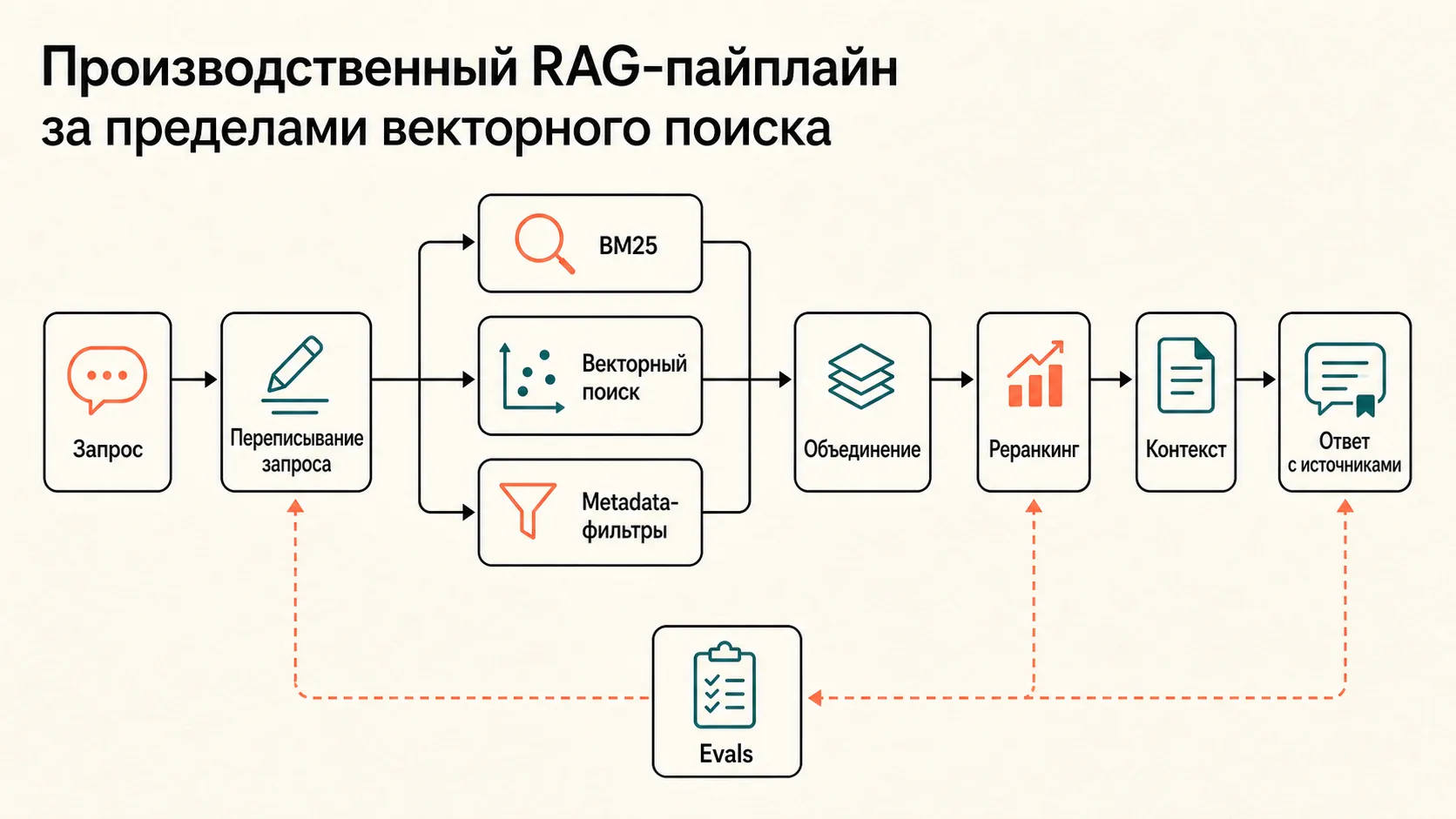
Практически это означает:
- Ingestion: забираем документы, записи, таблицы и данные из систем.
- Normalization: чистим текст, выделяем поля, сохраняем даты, ID и связи.
- Chunking: режем материал так, чтобы chunk отвечал на реальный вопрос, а не ломал таблицу посередине.
- Hybrid retrieval: ищем и по смыслу, и по точным словам.
- Fusion: объединяем кандидатов из разных поисков.
- Reranking: переоцениваем top-кандидаты моделью или cross-encoder подходом.
- Context assembly: собираем короткий, полезный контекст для LLM.
- Answering: отвечаем с источниками и понятной зоной уверенности.
- Evals: проверяем, что retrieval достал нужное, а ответ не добавил фактов.
Automotive RAG Assistant: где векторный RAG провалился
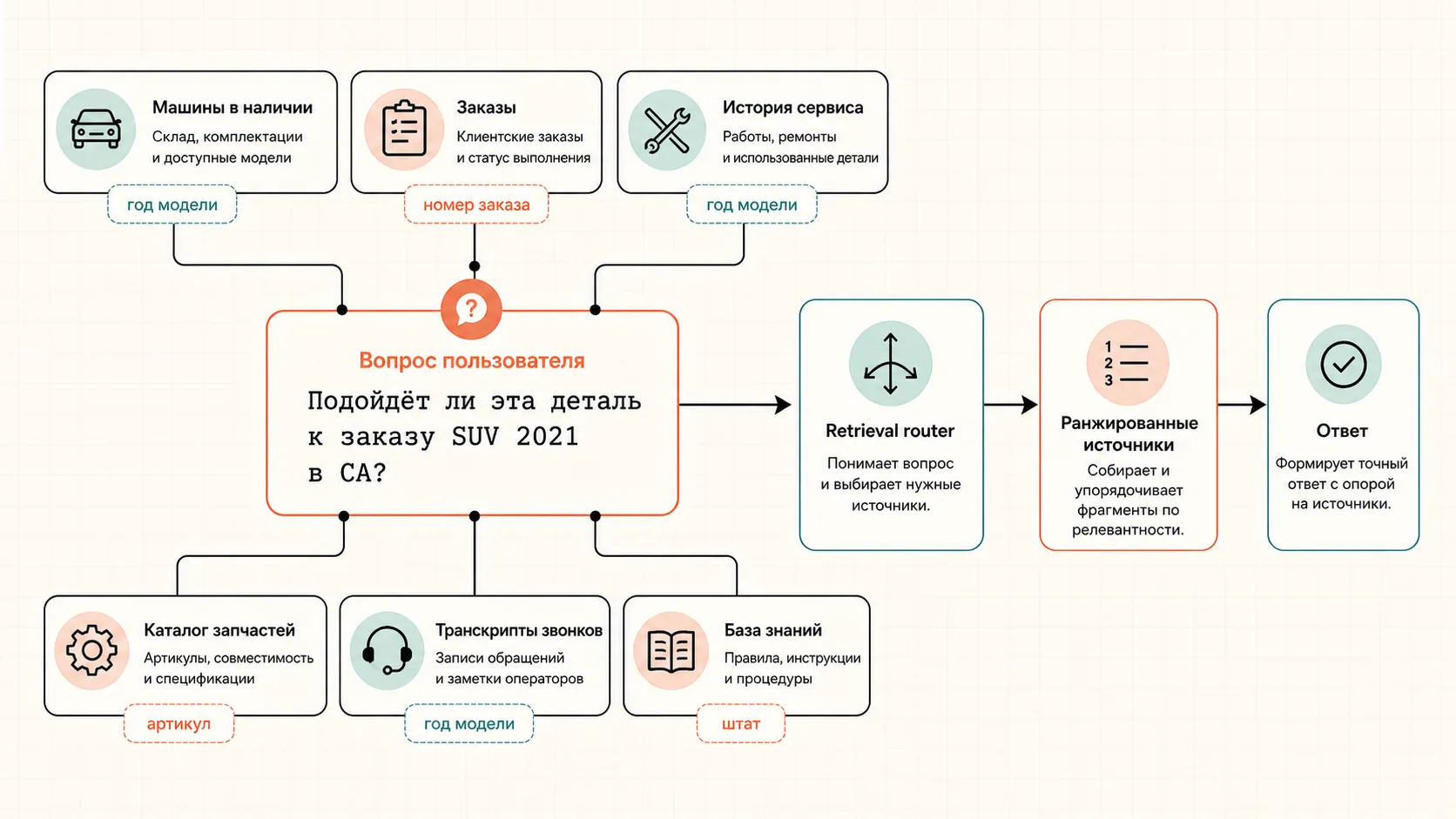
Кейс начался с понятной бизнес-идеи: у автомобильной компании много контактов с клиентами — письма, сообщения, звонки, заказы, сервис, машины, запчасти. Хотелось, чтобы ассистент во время работы менеджера подтягивал релевантную информацию: обсуждают машину — показать данные по машине; обсуждают заказ — показать статус; спрашивают про совместимость — найти правило и источник.
Первая версия была классической: документы нарезали на chunks, векторизовали, положили в vector DB, запрос пользователя тоже векторизовали, ближайшие фрагменты отдавали модели. Технически всё выглядело как RAG. На практике менеджеры получали нерелевантные подсказки, отвлекались и начали относиться к системе хуже, чем к отсутствию системы.
Главная причина была не в “плохой LLM”. Retrieval доставал не те фрагменты. А если контекст неверный, финальный ответ уже не спасает ситуацию.
Что поменяли в retrieval
Первое важное изменение — обратная связь. В интерфейсе появились лайки, дизлайки и короткий фидбек: что именно было не так. Сначала люди почти не пользовались этим, но когда им объяснили, что это напрямую улучшает систему, фидбек стал полезным сигналом для команды.
Дальше появились синтетические retrieval evals. Система брала chunk, генерировала возможные вопросы, на которые этот chunk должен отвечать, и проверяла: вернёт ли retrieval нужный источник. Так можно было быстрее мерить precision и recall, не дожидаясь каждого живого разговора.
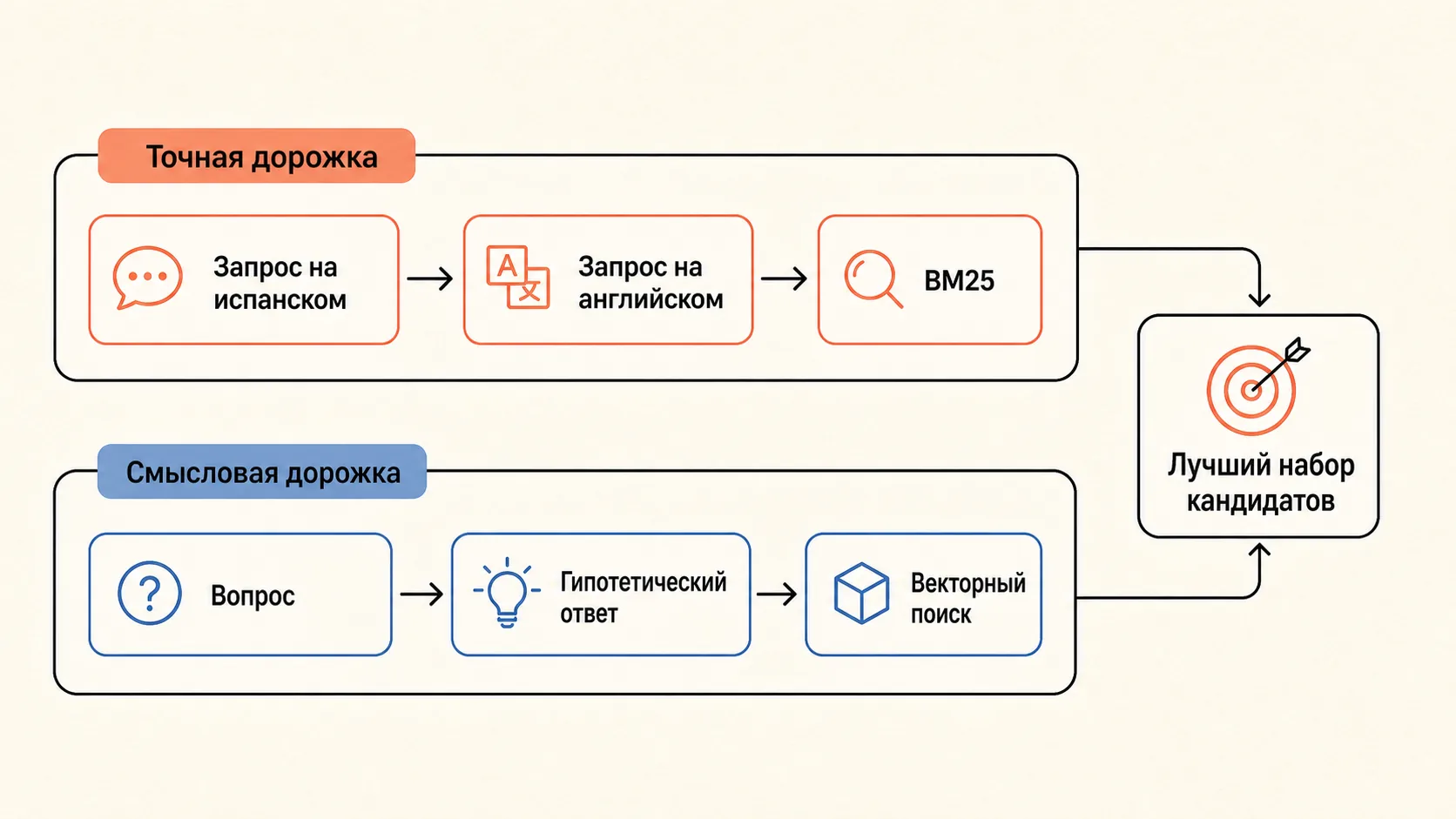
Самый большой пласт ошибок был связан с точными идентификаторами: номер заказа, артикул детали, конкретная модель, год, серия, штат. Для этого добавили полнотекстовый поиск. Не “вместо” векторного, а рядом с ним.
Потом обнаружилась языковая проблема: часть запросов приходила на испанском, а полнотекстовый поиск по английским источникам их не находил. Решением стала трансформация запроса: перевести или нормализовать запрос перед поиском. Для смысловой части похожий приём — HyDE: сначала сгенерировать гипотетический ответ, а уже его использовать для векторного поиска.
Следующий шаг — структурировать данные. Вокруг проекта были PDF, транскрипты звонков, заметки, данные по машинам, заказам и запчастям. Внутри этого хаоса всё равно жили поля: ID, дата, модель, статус, город, комплектация, артикул. LLM хорошо подходит для extraction, а дальше эти поля можно положить в SQL или использовать как metadata.
После этого RAG стал отвечать на вопросы другого уровня:
- “Готов ли заказ
S12345?” - “Подойдут ли литые диски R17 с артикулом
DSK-567на Mazda CX-5 2020 года?” - “Сколько в среднем занимает доставка заказов в Калифорнию?”
- “Какая машина сейчас дольше всего не продаётся?”
Это уже не просто поиск похожего абзаца. Это поиск по нескольким источникам с точными фильтрами, доменной логикой и ранжированием.
Где нужен Agentic RAG
Обычный RAG часто работает в одну сторону: пользователь задал вопрос, система сделала один поиск, собрала контекст, отправила один запрос в LLM. Для простых вопросов это нормально.
Но составные вопросы требуют нескольких шагов. Например: “подберите машины по этим критериям”, “сравните модель A и модель B”, “что сейчас происходит с ремонтом этой машины и какие детали уже заказаны”. Здесь система должна решить, куда идти: в vector search, full-text, SQL, историю сервиса или каталог запчастей.
Agentic RAG добавляет цикл рассуждения и tools. У агента есть инструменты: векторный поиск, BM25, SQL, возможно CRM или внутренняя база. Он может сделать первый поиск, увидеть ноль результатов, переформулировать запрос, заменить аббревиатуру на нормальный термин и попробовать снова.
Это повышает качество на сложных вопросах, но не бесплатно. Агентный сценарий медленнее и дороже: больше запросов, больше токенов, больше ветвлений. Поэтому его стоит включать не везде, а там, где evals показывают выигрыш.
Как тестировать RAG
Главное правило: retrieval и generation нужно проверять отдельно.
Если система не достала нужный источник, бесполезно ругать финальный ответ. Модель могла красиво сформулировать, но ей дали не тот контекст. Если retrieval достал правильный источник, а модель всё равно добавила лишний факт, тогда смотрим prompt, модель, правила отказа и формат ответа.
Более общий подход к проверкам разобран в статье Зачем AI-проекту evals. RAG быстро показывает, зачем отделять component tests от end-to-end проверок.
Минимальный набор проверок:
- Recall: нашла ли система нужные источники.
- Precision: сколько среди найденного мусора.
- Source coverage: хватает ли источников для ответа.
- Faithfulness: не добавил ли ответ факты вне контекста.
- Latency: успевает ли система ответить в реальном рабочем сценарии.
- User feedback: помогает ли ответ человеку, а не просто проходит тест.
В Automotive RAG Assistant именно feedback loop и synthetic evals ускорили итерации. Без этого команда бы неделями спорила “кажется стало лучше” вместо того, чтобы видеть, какой слой реально сломался.
Что важно запомнить
RAG — это не “подключить документы к ChatGPT”. Это retrieval system внутри AI-продукта. Векторный поиск полезен, но он не обязан быть центром архитектуры.
Если в данных есть точные ID, артикулы, таблицы, статусы, роли доступа и живые операционные процессы, почти всегда нужны hybrid search, metadata, reranking и evals. Если вопросы составные — иногда нужен Agentic RAG. Если данные плохо структурированы — часто сначала нужно извлечь структуру, а уже потом красиво отвечать.
Хороший RAG не обещает, что модель “знает документы”. Он показывает, какие источники нашёл, почему они подходят, где данных не хватает и как качество меняется после обновления базы знаний.